
At AutonomyAI, we’re constantly evaluating the latest LLMs to improve our agent performance, especially in the context of front-end development. So when Grok 4 was released and topped many of the standard benchmarks, the hype was real. We eagerly put it through its paces within our design-to-code agent flow to see if it could outperform our current go-to model, Claude. The results? Let’s just say, newer doesn’t always mean better.
Visual Rendering: Claude Wins by a Margin
At AutonomyAI, our design-to-code agents usually include a visual feedback loop: once an agent renders an output, it reviews how closely it matches the original Figma and iterates to improve the result. But for this benchmark, we disabled that loop.
Why? To normalize evaluation. Some models need multiple tries to land a usable result so comparing them with feedback loops enabled introduces noise around latency and consistency. Instead, we measured performance based on a single rendering pass from design to code.
And even in this first-pass-only scenario, the results were dramatically different.
See for yourself:

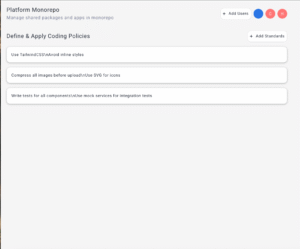

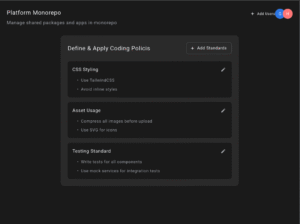
While our initial benchmark used a single screen, we added a second example to verify the gap wasn’t an outlier—and the difference held up.
- Grok 4 misaligned sections, ignored font and spacing guidelines, and failed to honor design hierarchy.
- Claude showed strong consistency with Figma, preserving layout logic, spacing, and component grouping with minimal hallucination.
For a design agent, these aren’t minor misses; they’re make-or-break problems. When teams rely on agents for visual implementation, hallucinated layout or missing structure erode trust fast. Claude passed that baseline. Grok 4 didn’t.
Latency: 2x-5x Slower in Practice
While benchmark latency claims vary by context, we ran a controlled, single-run test to get a real-world snapshot of model responsiveness inside our agent workflow. Even in this one-off session, Grok 4 consistently lagged behind Claude.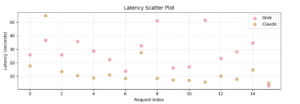
This chart shows how long each model took (in seconds) across 16 prompt executions. While Claude hovered around the 10-second mark, Grok’s latency often spiked above 30 seconds, with a median latency nearly 3× higher than Claude. The result wasn’t just a slower experience—it introduced variability and broke the user flow.
In interactive systems like ours—where agents collaborate with developers in real time—this level of delay becomes a blocker. Slower feedback loops kill development momentum, and Grok just couldn’t keep up.
Quality Feedback: Grok Was Too Polite
One of the most surprising outcomes was Grok’s evaluation of existing components. We use a strategy we call PACT (Product-Facing Work, Architecture Hygiene, Communicating Logic, Task Definition) to guide how agents evaluate and upgrade components during development.
Claude consistently found areas to improve: issues like missing TypeScript interfaces for props, lack of reusable configurations, absence of proper error handling, weak documentation, and accessibility oversights were flagged and refactored.
Grok 4, on the other hand, surprisingly approved nearly everything. This was especially unexpected given Grok’s reputation as one of the more critical and less agreeable LLMs by design, often providing blunt and unfiltered assessments. Instead, it provided minimal constructive criticism and rarely initiated improvements unless explicitly prompted. This uncharacteristically agreeable behavior limited its effectiveness as a collaborative agent in our design-to-code pipeline.
Conclusion: Claude Still Leads for Front-End Agents
While Grok 4 may have potential in other contexts, it falls short in the fast-feedback, high-precision world of front-end agent tooling. From slower response times to less critical evaluations and weaker visual alignment, it underperformed Claude on every front that matters to us.
We’re hopeful that future iterations of Grok will close the gap. For now, Claude remains our top choice when it comes to building reliable, visually-aligned, and opinionated development agents.
TL;DR
- Claude outperforms Grok 4 in visual fidelity, latency, and critique quality.
- Grok 4 may be promising in other use cases, but it is not ready for production design-to-code agent workflows.
- PACT-guided agent development demands assertiveness and visual accuracy—Grok 4 misses both.


