
The generative AI arms race isn’t slowing down. OpenAI’s GPT-5 is here, Anthropic’s Claude Opus has already been making waves, and everyone’s wondering: Which is better for real development work?
At AutonomyAI, we put that to the test not by running toy prompts, but by using them in our Design-to-Code AI agent pipeline, where models need to behave like real engineers inside a real codebase. This means following file structure conventions, obeying system rules, and producing maintainable code.
How We Tested
Our setup mirrors how we use LLMs in production:
- For GPT-5, we use GPT-4.1 as a “context collector” over dozens of targeted prompts. GPT-5 then does the heavy lifting, generating code within the constraints of the repo.
- For Claude, we mirrored this with Claude Sonnet gathering the context and passing it to Claude Opus 4.1 for the final work.
- We tested across runs with identical Figma designs and “vibe coding” (design-less builds using only textual descriptions). We tried both image input and text-only descriptions of the same images to measure whether models rely too heavily on visual cues.
We also collected metrics on quality, speed, and cost.
Benchmark disclaimer: At AutonomyAI, our design-to-code agents usually include a visual feedback loop: once an agent renders an output, it reviews how closely it matches the original Figma and iterates to improve the result. But for this benchmark, we disabled that loop.
What We Found
1. GPT-5 Fits the Team Player Role Slightly Better
In a collaborative dev environment, adherence to rules is everything. GPT-5 consistently:
- Followed codebase conventions more strictly
- Paid more attention to file structure, generating extra files when needed to keep things modular and within repo guidelines
Claude Opus 4.1 wasn’t far behind, but at times it felt like those rules would get lost in the context whereas GPT-5 felt more consistent in adhering to the rules in every run.
2. Output Quality: A Dead Heat
When we compared final visual results, there was no clear long-term winner. On some runs GPT-5 edged ahead, on others Opus 4.1 did, so we’re calling this a draw.
Here it is so you can see: the first is the raw Figma, then the Claude output, then the GPT-5 output.
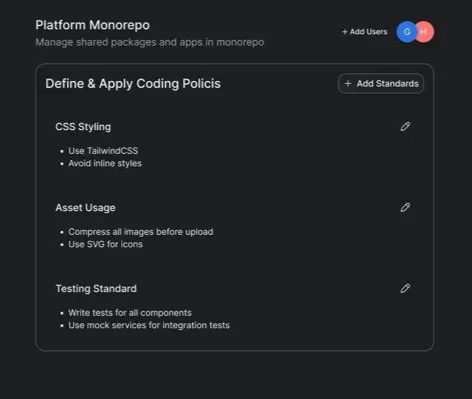
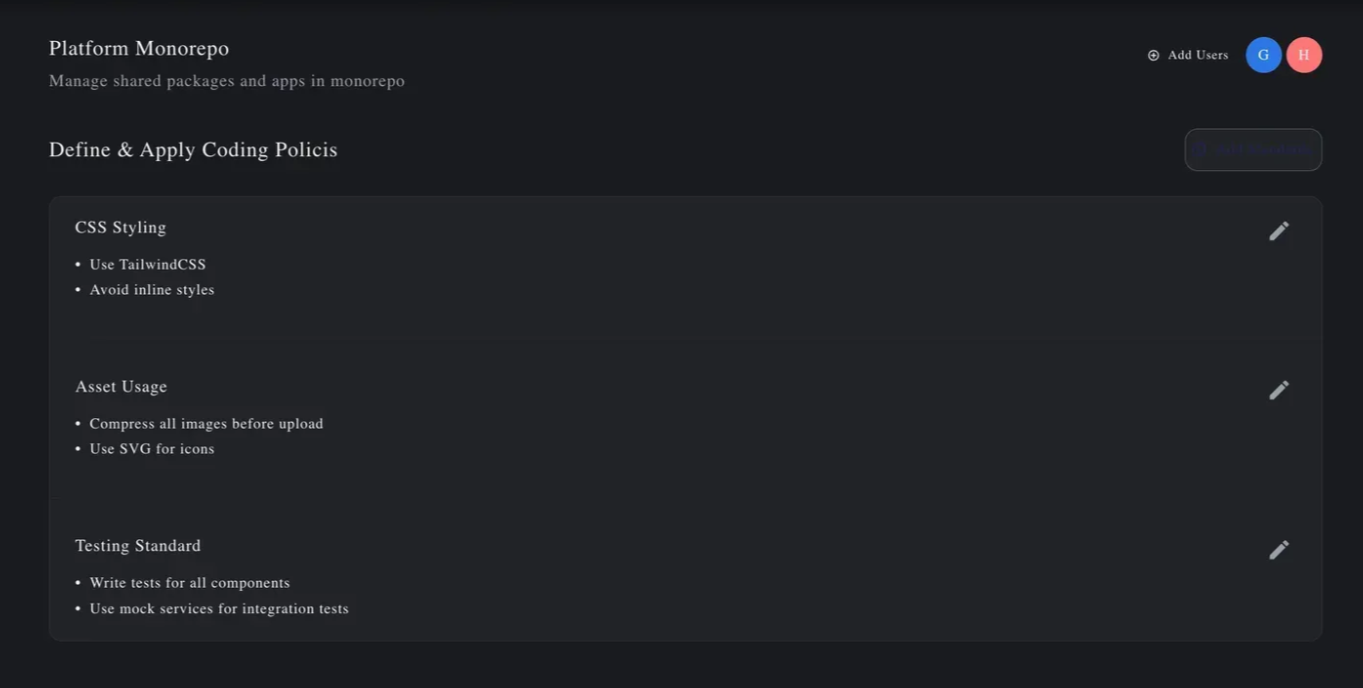
Below, we also ran the same comparison in text-only “vibe coding” mode, with no visual input.
3. Speed and Cost Trade-off
This is where things got interesting:
- Speed: GPT-5 was about 70% slower than Opus 4.1
- Cost: GPT-5 was about 75% cheaper to run for the same work
If you’re running an agent fleet at scale, that cost difference can be transformative, even if you give up some latency.
4. Great With or Without Images
Both models performed better with Figma/image input, but both also did impressively well with “vibe coding,” building just from detailed text descriptions.
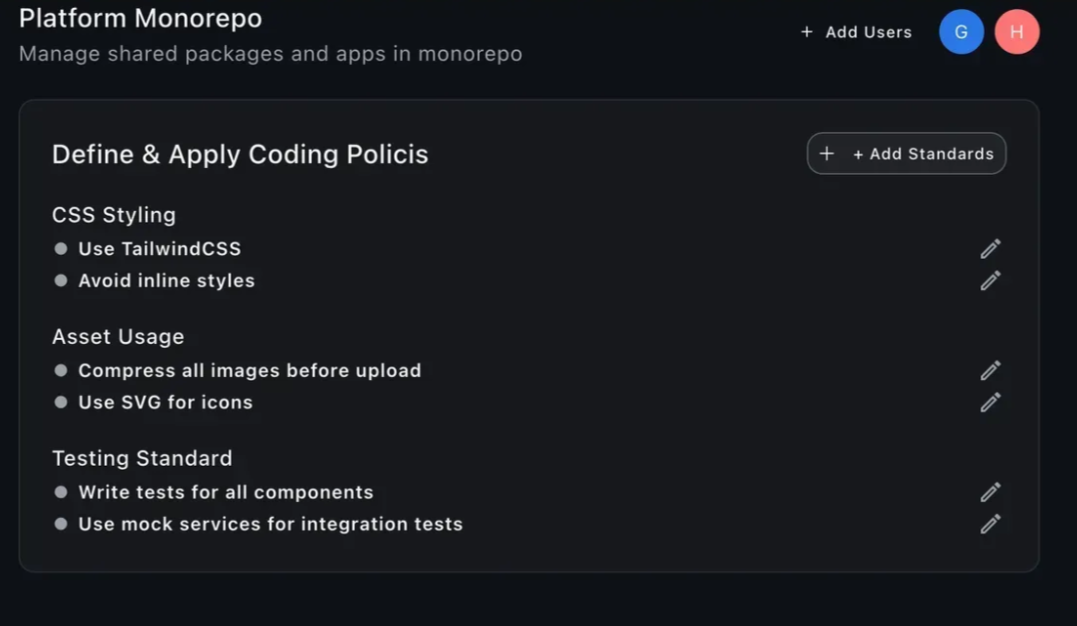
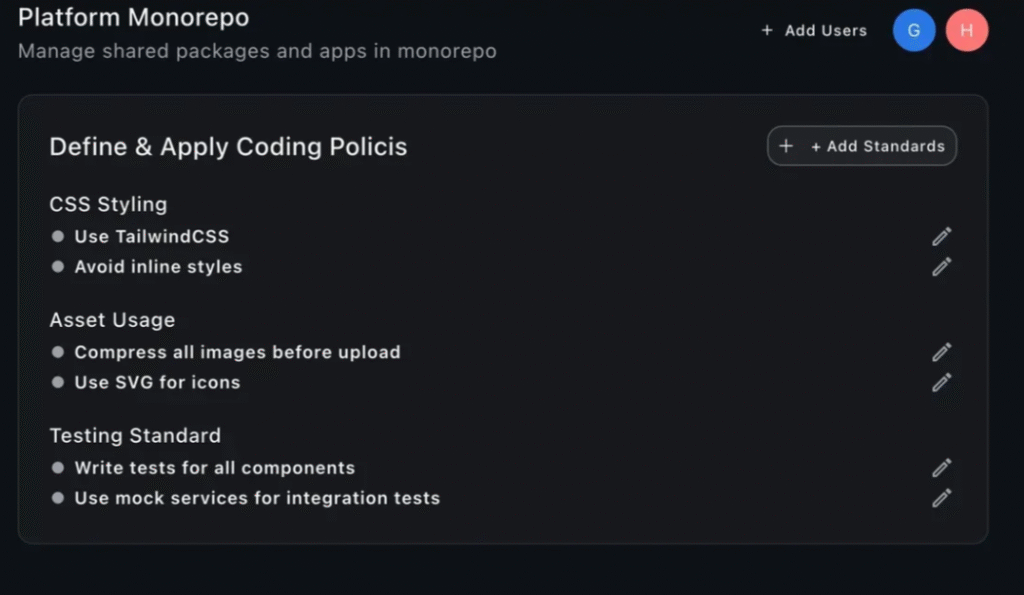
Below we’re showing the same screen from the earlier example, but this time we only passed the ticket description with no design file at all. First is the Claude output, then the GPT-5 output.
The key takeaway is that both models demonstrated a strong ability to understand feature requests and implement them without visual references. This matters because some of our clients now use Figma less in their workflows, relying instead on vibe coding directly in their codebase. That shift means designs can be implemented faster without waiting for full Figma mockups, removing the designer bottleneck and accelerating development.
It’s encouraging to see both models excel in this mode as well, since it opens new possibilities for how teams plan and execute work.
The Bigger Picture
Here’s the takeaway:
- No, GPT-5 isn’t some wild quantum leap over Claude Opus 4.1 in pure capability, at least not in this domain
- Yes, it’s far more economical, which matters a lot if you’re running continuous development agents
- And most importantly, great tooling has been able to get this quality from LLMs for a while now. Our advanced pipelines have delivered top-tier code from earlier models by structuring the work, enforcing standards, and managing context intelligently
While economics are important, quality is king for us. In production, we’ll actually be using both models together so they can catch each other’s mistakes, leveraging the visual feedback loop we mentioned earlier that wasn’t part of this benchmark.


